I started building edwardcho.dev as a way to better understand the editorial CMS patterns I work with professionally. I did not want the site to be just a static portfolio. I wanted to build something with real authoring workflows: drafts, revisions, publication state, and the kinds of tradeoffs that show up when content is treated as a system instead of a collection of pages.
The first version leaned hard into that idea. I used Clerk so visitors could sign up and enter the editor themselves. At the time, that felt like the most direct way to make the project interactive. If the editor was one of the most interesting parts of the system, letting people use it seemed like the obvious move.
Over time, that stopped feeling like the right architecture for the site. Requiring sign-up created friction for a personal site. More importantly, letting unknown users create content pushed the project toward becoming a multi-tenant app instead of a personal publishing platform. That meant thinking about abuse, data cleanup, stronger isolation, and whether I actually wanted to operate a shared editor on top of my own site.
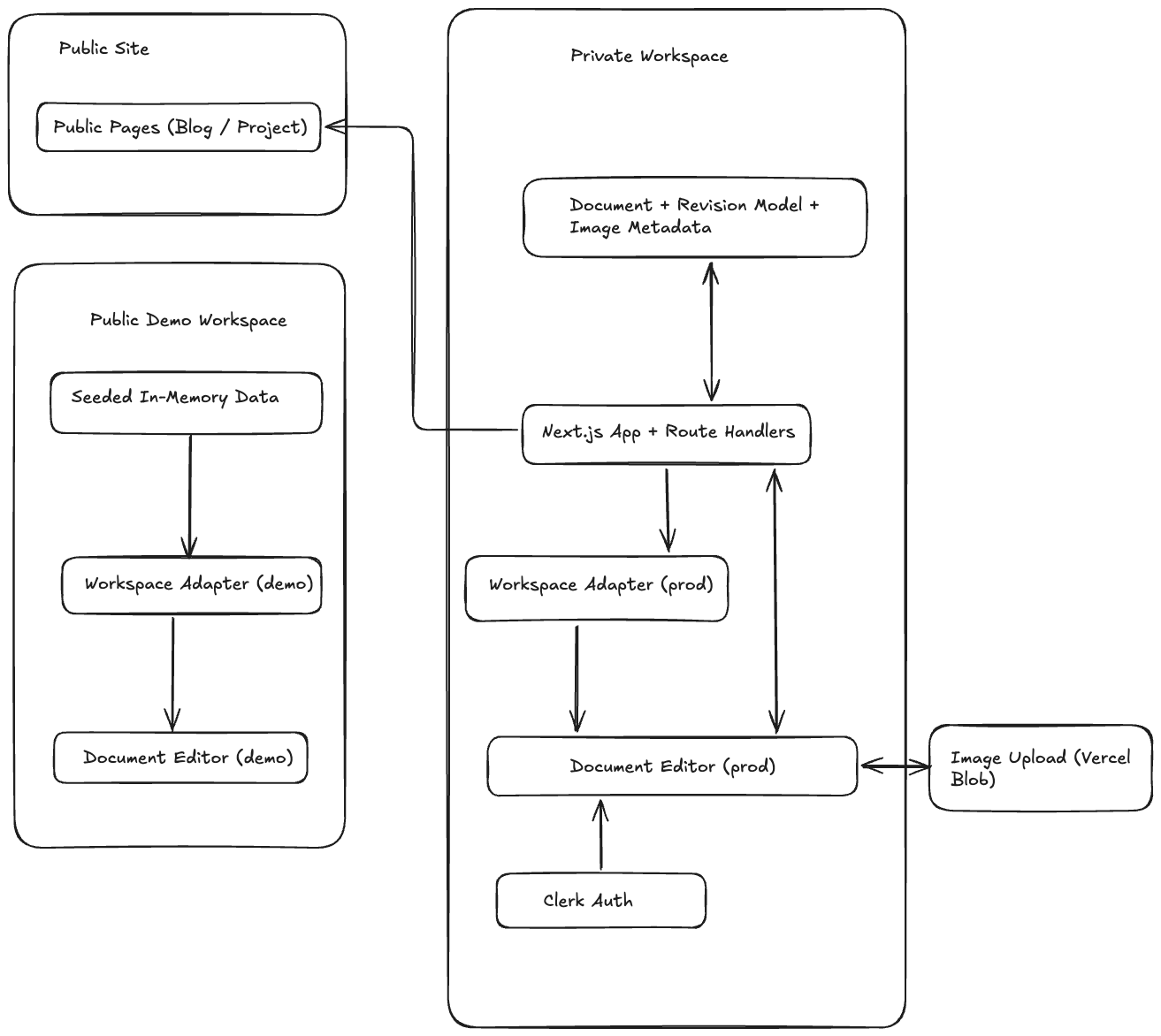
The current architecture is the result of narrowing that scope. The system now has a private editorial workspace, public pages derived from the same document model, and a separate public demo for showing the workflow without exposing production. The choices behind that structure are what make the project interesting.
Why the editor became private
The biggest architectural shift was deciding that the production editor should not be a public feature.
Originally, public access felt like a strength. It made the project feel more product-like, and it gave visitors something interactive to explore. The problem was that openness was pulling the system in a different direction than the one I actually cared about. A public editor is not just an interface choice. It implies tenant boundaries, stronger data ownership rules, moderation concerns, and long-term responsibility for user-created content.
For a personal site, that was the wrong complexity.
So I moved the real editor into a private, publisher-only workspace. That made the system much more coherent. The editorial surface now exists to support my own writing and publishing workflow, not to act as a lightweight SaaS product for anyone who lands on the site.
The tradeoff was openness versus clarity. I gave up the simplest possible demo story, but I gained a cleaner security model, less operational noise, and a better fit between the system and its actual purpose.
The alternative would have been to keep the editor open and properly embrace multi-user architecture. That would mean more explicit tenancy in the data model, stronger abuse controls, and more admin surface area. That is a valid product path, but it is not the one this project ultimately needed.
Why I modeled documents as revisions
Once the editor became a real publishing workspace, revision history stopped feeling optional.
That is why the current model treats Document as the durable container and Revision as the evolving content. The document owns identity, ownership, publication metadata, and the pointer to the latest revision. The revision owns the title, content, revision number, author, and timestamp.
This structure matters because it makes revision history part of the architecture instead of an afterthought. A document is not just the latest title and body stored in a row. It is a stable object that accumulates editorial states over time.
A key signal here was moving title data into Revision instead of keeping it on Document. That made the model more honest. If a title changes as the content evolves, then it belongs with the revisioned content.
The tradeoff is more write complexity. Updating a document means creating a new revision and updating latestRevisionId, not simply mutating the current row. Reads also have to care about the latest revision relationship more often.
The alternative would have been a simpler mutable-document model with maybe an audit trail on the side. That would be easier to build at first, but it would not support revision comparison, editorial history, or more structured publish behavior nearly as naturally.
Why I moved from Express to Next.js Route Handlers
I started with Express because I liked the separation between UI and API. It felt cleaner to keep the backend distinct and let the frontend consume it over an explicit boundary.
That structure made sense early on, but over time it stopped buying me much. The app had one frontend, one deployment target, one set of auth rules, and one tightly related set of document workflows. The separation was becoming more ceremonial than useful.
Moving the API into Next.js Route Handlers simplified the system in a way that matched the real scope of the project. Auth checks, validation, mutations, and rendering logic now live in one app surface. Deployment is simpler. Local development is simpler. Later integrations, especially the Vercel Blob upload flow, fit naturally inside the same application boundary.
The tradeoff was separation versus simplicity. A distinct backend can be the right choice when multiple clients exist, when service boundaries need to be strong, or when the domain needs to scale independently. In this project, those benefits were mostly theoretical. The cost of coordinating two app surfaces was more real than the benefits of keeping them apart.
So I traded some architectural purity for a system that is easier to ship and easier to maintain.
How publishing works in the current model
Publishing in the current system is intentionally lightweight. There is not a separate published-content table or a second public-content pipeline. Instead, the same Document record gains public metadata like kind, slug, excerpt, status, and publishedAt. Public pages then read from that same document, including its latestRevision.
That means publication is modeled as state on the editorial object rather than as a separate release artifact.
The upside is simplicity. There is one source of truth. There is no synchronization between draft content and published content. There is no separate publish table to keep in sync. A public page is just the latest revision of a document that has been marked public.
The downside is that draft editing and public release are more tightly coupled. In the current implementation, once a document is published, saving a new revision updates the public page after revalidation. You do not need to unpublish and republish to keep editing. That is convenient, but it also means the system does not distinguish very strongly between “current draft in progress” and “current public release.”
An alternative would be snapshot publishing. In that model, publishing would create a separate public record tied to a specific revision. Draft work could continue privately without affecting the public site until the next publish action. That is a more formal editorial model, but it also introduces more tables, more synchronization logic, and more workflow complexity than this project currently needs.
For this project, the current model felt like the right tradeoff: simpler to reason about, even if it is less strict than a fuller publishing pipeline.
Why I built a public demo instead of exposing production
Once I made the real editor private, I still wanted a way to show the workflow publicly. The answer was not to reopen production. It was to separate the UI from the backing implementation.
That led to the adapter pattern in the document workspace. The production workspace talks to the real API routes. The demo workspace uses seeded in-memory data but exposes the same overall capabilities: load documents, create drafts, save revisions, change publish state, and simulate image insertion.
This was one of the most useful abstractions in the project because it let me keep the interactive part of the story without weakening the boundary around the real system.
The tradeoff is extra structure. I had to define and maintain a workspace contract that both production and demo implementations satisfy. For a smaller app, that is more abstraction than strictly necessary. But it paid off by making the demo feel real without making production more exposed.
The alternative would have been a static walkthrough, screenshots, or a read-only page explaining the workflow. That would have been simpler, but also much less compelling.
Supporting tradeoffs that shaped the current system
A few other decisions matter, even if they are not the main architectural story.
Public pages use static generation with targeted revalidation, while the private workspace stays dynamic. That split reflects two different priorities: performance for public readers and freshness for editorial work.
Image uploads use a two-step flow. The app first authorizes the upload through an API route, then the file uploads to Vercel Blob, then a second registration route verifies the blob and stores metadata linked to the document. That is more moving pieces than storing everything in one place, but it keeps binary storage and relational metadata in the right systems.
Authentication is handled by Clerk, while authorization stays deliberately simple through a publisher allowlist. That is not a full role system, but it matches the actual needs of the app.
The editor also tracks dirty state so saving a revision and publishing are treated as different actions. That is a smaller decision, but it reinforces the underlying model instead of hiding it behind “smart” UI behavior.
What I intentionally did not build
The easiest way to overcomplicate a project like this is to optimize it for imaginary future requirements.
I did not build a true multi-tenant editor.
I did not build a full RBAC system.
I did not build a separate publish service or a separate public content store.
I did not build collaboration, approvals, or a richer editorial workflow engine.
Those are all reasonable directions. They just were not necessary to make this system good at its actual job.
Conclusion
What began as an attempt to recreate professional editorial workflows in a personal project became a smaller, more opinionated system: a private editorial workspace, a revision-aware content model, tightly integrated app and API boundaries, and public pages derived from the same source of truth.
Some choices landed on the side of simplicity, some on correctness, and some on product clarity. Taken together, they made the site less like a generic portfolio or public writing app, and more like a focused personal publishing platform.
That is probably the clearest summary of the architecture now: not a portfolio with CMS features attached, but a small editorial system designed around the tradeoffs I actually care about.